Mycat

Mycat数据库中间件,MyCat 不存储数据,它只是数据的路由
集群基于ZooKeeper管理,分库分表,虚拟数据库
Mycat入门
下载mycat导入到idea:
配置 schema.xml
MyCat 连接物理库、配置虚拟库、虚拟表都需要在 schema.xml 中配置
配置详情
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 配置虚拟库,虚拟表-->
<schema name="romdb" checkSQLschema="true">
<!--配置了表在mycat数据库里面才会显示,不然没有表数据-->
<table name="virtual_t_emp"
dataNode="data-node-hello"
subTables="t_emp"
primaryKey="emp_id"
autoIncrement="true"
>
</table>
</schema>
<!-- 配置物理库-->
<dataNode name="data-node-hello" dataHost="virtual-host-hello" database="db_hr" />
<!-- 封装物理服务器给外界引用-->
<dataHost name="virtual-host-hello" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc">
<!-- 心跳检查-->
<heartbeat>select user()</heartbeat>
<!-- 连接物理库服务器-->
<writeHost host="mysql"
url="jdbc:mysql://localhost:3306"
user="root"
password="root">
</writeHost>
</dataHost>
</mycat:schema>
配置 server.xml
配置 MyCat 自身的连接信息
配置详情
<!-- name 属性:指定用户名。 -->
<user name="myCat">
<property name="password">root</property>
<!-- schemas 属性:要连接的虚拟库的名称。 schema.xml 配置文件中找到 schema 标签 -->
<property name="schemas">virtual-db-hello</property>
</user>
数据分片
从虚拟库、虚拟表看到的数据,逻辑上是一个整体。而实际上数据的物理存储是分散在不同物理库、物理表中。每个实际的物理表可以看成是一个数据分片
数据进入数据库时,经过不同拆分规则的分流进入了不同的数据分片
规则名称是在 rule.xml 中定义:
在 table 标签中通过 rule 属性指定规则名称即可
具体分类:
- 取模分片
- 全局 id 分片
- 枚举分片
- 固定 hash 分片
- 固定范围分片
- 取模范围分片
- 字符串 hash 分片
- 时间分片
- 一致性 hash 分片
取模分片
根据 id 值进行模运算,然后根据取模的计算结果决定数据分流后存入的目标物理表
此时还没有执行 insert 语句,数据库无法使用自增id进行取模运行,所以id需要自己生成,在插入数据库
配置 subTables 属性
schema.xml 配置文件中 schema 标签的子标签 table 的 subTables 属性
- 单个值:t_user
- 多个物理表名称用逗号隔开:t_user1,t_user2,t_user3
- 或者使用正则指定数值区间: t_user$1-5
- 将多个用区间表示的物理表名称用逗号隔开:t_user1-5,t_user7-10
配置拆分规则
在 schema.xml 中配置 rule 属性
取模分片的名称是 mod-lang
<!-- 取模分片 -->
<!-- 配置 1:通过 subTables 属性指定物理表 -->
<!-- 配置 2:通过 rule 属性指定拆分规则 -->
<table name="virtual_t_emp"
primaryKey="emp_id"
dataNode="data-node-hello"
autoIncrement="true"
fetchStoreNodeByJdbc="true"
subTables="t_emp$1-3"
rule="mod-long"
/>
在 rule.xml 中配置 mod-long 规则
<tableRule name="mod-long">
<rule>
<!-- 指定用于执行取模分片的字段 -->
<columns>emp_id</columns>
<!-- 具体规则名称 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- 物理表的数量,需要正好就是取模的数值 -->
<property name="count">3</property>
</function>
重启Mycat,插入数据,自动分流到三个数据库
- t_emp1
- t_emp2
- t_emp3
全局 id 分片
全局 id 分片和上面的取模分片就一个区别:id 的来源不同
取模分片:人工提供 id 值。
全局 id 分片:由 MyCat 提供 id 值。
MyCat 提供 id 值有下面这些办法:
- 基于本地文件
- 基于数据库
- 基于 zookeeper
- 基于时间戳
基于本地文件
配置 sequence_conf.properties
#配置主键id统一自增
# 使用过的历史分段,可不配置
USER.HISIDS=
# ID 的起始值,从这个值开始生成 ID
USER.MINID=1
# 最大ID值
USER.MAXID=99999999999
# 当前ID值
USER.CURID=10
配置 server.xml
<!--设置全局序号生成方式
0:文件
1:数据库
2:时间戳
3:zookeeper
-->
<property name="sequenceHandlerType">0</property>
插入要求
next value for MYCATSEQ_ 是固定格式
USER 是 sequence_conf.properties文件中配置的前缀
INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES('next value for MYCATSEQ_USER', 'jerry01');
基于数据库
执行MyCat 自带的一个 SQL 文件:dbseq.sql
在 MYCAT_SEQUENCE 表中增加一条记录
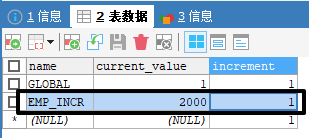
配置 sequence_db_conf.properties
EMP_INCR=data-node-hello
配置 server.xml
<!-- 指定全局 id 分片方式 -->
<!-- 0 表示基于文件 -->
<!-- 1 表示基于数据库 -->
<property name="sequenceHandlerType">1</property>
插入数据
INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES('next value for MYCATSEQ_EMP_INCR', 'kate01');
基于时间戳
配置 server.xml
<!-- 指定全局 id 分片方式 -->
<!-- 0 表示基于文件 -->
<!-- 1 表示基于数据库 -->
<!-- 2 表示基于时间戳 -->
<property name="sequenceHandlerType">2</property>
配置 sequence_time_conf.properties
WORKID 与 DATAACENTERID 都是 0-31 任意整数。多 mycat 节点下,每个节点的 WORKID、DATAACENTERID 不能重复,组成唯一标识
#sequence depend on TIME
WORKID=05
DATAACENTERID=05
物理表id 字段宽度,必须使用 bigint 类型
next value for MYCATSEQ_ 后面可以随便写
INSERT INTO virtual_t_emp(emp_id, emp_name) VALUES('next value for MYCATSEQ_FOO', 'BOB01');
固定范围分片
配置 schema.xml
<!-- 固定范围分片 -->
<!-- 配置 rule 属性:auto-sharding-long -->
<table name="t_emp"
primaryKey="emp_id"
dataNode="data-node-male,data-node-female"
autoIncrement="true"
fetchStoreNodeByJdbc="true"
rule="auto-sharding-long"
/>
配置 rule.xml
<tableRule name="auto-sharding-long">
<rule>
<!-- 指定用于做 hash 运算的字段 -->
<columns>emp_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
配置 autopartition-long.txt
# range start-end ,data node index
# K=1000,M=10000.
# 0-500M=0
# 500M-1000M=1
# 1000M-1500M=2
0-20=0
21-50=1
数据插入
INSERT INTO t_emp(emp_id,emp_name,emp_gender) VALUES(2,'jack13','male');
跨库 join
A 表和 B 表做关联查询,但是 A 表和 B 表不在同一个数据库中
全局表
为了避免频繁的跨库join操作,结合冗余数据思想,可以考虑把这些字典信息在每一个分库中都存在一份。
mycat在进行join操作时,当业务表与全局表进行聚合会优先选择相同分片的全局表,从而避免跨库join操作。在进行数据插入时,会把数据同时插入到所有分片的全局表中。
修改 schema.xml
<table name="tb_global" dataNode="dn142,dn145" primaryKey="global_id" type="global"/>
ER表
ER 表也是一种为了避免跨库join的手段,在业务开发时,经常会使用到主从表关系的查询,如商品表与商品详情表。
ER 表的出现就是为了让有关系的表数据存储于同一个分片中,从而避免跨库 join 的出现。
修改 schema.xml
<table name="tb_goods" dataNode="dn129,dn130" primaryKey="goods_id" rule="sharding-by-murmur-goods">
<childTable name="tb_goods_detail" primaryKey="goods_detail_id" joinKey="goods_id" parentKey="goods_id"></childTable>
</table>